Karta – Matching Open Sources in Binaries
March 21, 2019

Research by: Eyal Itkin
Introduction
“Karta” (Russian for “map”) is a source code assisted binary matching plugin for IDA. The plugin was developed to match symbols for an open source library in a very large binary, usually a firmware file. For those who deal daily with firmware files, it’s a waste of time to have to repeatedly reverse net-snmp; there is a clear need for a tool to identify the used open sources, and automatically match their symbols in IDA.
The original focus was for the matching process to happen quickly. Waiting several hours just for matching a library of 300 functions isn’t acceptable, even if the binary we are trying to reverse engineer contains more than 100,000 functions. However, combining several lessons from the reverse engineering trade enabled us to solve this problem, with better than expected results.
It turns out that the heuristics we deployed for performance reasons had great impact on the matching results as well. The plugin produced very low False Positive ratios, together with high True Positive ratio. This made it useful even for matching small to medium binaries, which wasn’t on our initial agenda.
Therefore, we feel Karta can be an important tool in the researcher’s toolbox, and will be useful in the following scenarios:
Karta
As described previously, Karta is a source code assisted binary matching plugin for IDA*. The plugin achieves 2 important research goals:
The plugin is now open source, and can be found in our Github.
As compiling open source libraries on different architectures can sometimes be a painful task, we removed this step by making our plugin architecture independent. For example, if we want to match version 1.2.29 of the libpng open source (the one that is used in our HP OfficeJet firmware), all we have to do is to clone it from Github and compile it on our (x86) machine. After it’s compiled, Karta can generate a canonical .json configuration file that describes the library. Using this configuration, our plugin can now successfully locate the library in the firmware, even though the firmware was compiled to Big-Endian ARM Thumb mode.
*Karta consists of modules, and the IDA disassembler module can be replaced by any other disassembler module. Thanks to @megabeets_, support for radare2 is now in the final development phases.
Finding 1-Days
While we described several use cases for our plugin, finding 1-days in popular software is probably the most interesting. Here are two real life examples we found during our research.
HP OfficeJet Firmware
During our FAX research, we needed a 1-Day to use as a debugging vulnerability. Eventually, we used Devil’s Ivy. After we finished developing Karta, it was time to turn back to our firmware and check how Karta could have helped us in our research.
The identifier plugin tells us that the used open source libraries in the firmware are:
Here we can see that gSOAP is indeed used, and a quick CVE search shows us that it contains a critical vulnerability: CVE-2017-9765 (Devil’s Ivy).
After we quickly compiled a configuration for this version of gSOAP, we ran our matcher and imported the matched symbols. Here we can see that the vulnerable code function soap_get_pi was matched by Karta:
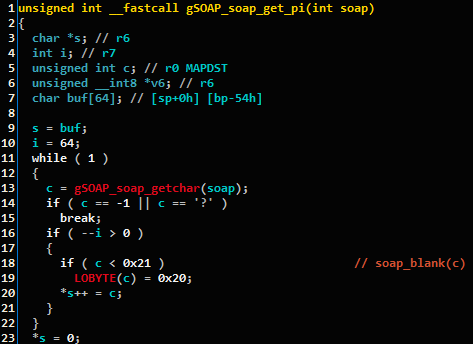
Figure 1: The decompiled soap_get_pi function, as matched by our plugin.
This is very good news for our plugin: it works as intended in a real-life scenario (too bad we only had it after we finished the FAX research).
Ordinary closed source program – TeamViewer
Easily finding 1-Days in firmware is handy, but what about day-to-day programs that we use on our Windows PC? While reading Project Zero’s blog post on WebRTC, we saw they found a vulnerability in a library called libvpx:
CVE-2018-6155 is a use-after-free in a video codec called VP8. It is interesting because it affects the VP8 library, libvpx as opposed to code in WebRTC, so it has the potential to affect software that uses this library other than WebRTC. A generic fix for libvpx was released as a result of this bug.
This looks interesting, as Project Zero specifically says this vulnerability “has the potential to affect software that uses this library other than WebRTC.” We have TeamViewer installed on our computer, and it sounds like it should use the same open source library, let’s check it out.
We opened TeamViewer.exe in IDA, and we started working while the analysis was in progress. We downloaded the latest version of libvpx (1.7.0), wrote a simple identifier for it, and added it to Karta. As we couldn’t wait for IDA to finish the analysis, we stopped it and run Karta’s identifier plugin. The identified open sources were:
TeamViewer not only uses libvpx, but uses an old version from January 2017.
Looking at the patch that Google issued, we know that the function of interest to us is vp8_deblock, which looks like this:
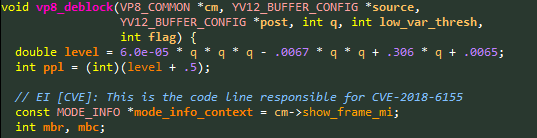
Figure 2: Code snippet of vp8_deblock function, vulnerable to CVE-2018-6155.
We told IDA to resume the analysis, and proceeded to compile a Karta configuration for libvpx, version 1.6.1. Once the configuration was ready, and after IDA finished analyzing the binary, we ran Karta’s matcher plugin. As you can see, the matcher found our vulnerable function:

Figure 3: Karta’s matching result show it matched the vulnerable function – highlighted in blue.
After we imported the results back to IDA, we can clearly see, using the numeric constants, that this was a correct match.
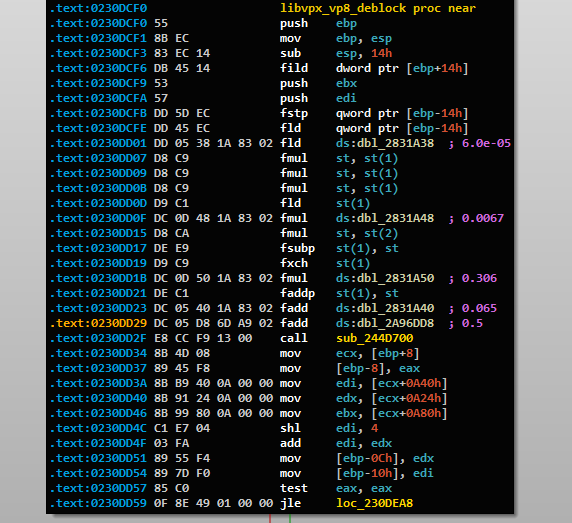
Figure 4: The vulnerable function, matched by our plugin, as seen in IDA Pro.
And there we have it, we found a vulnerability in the TeamViewer program, and we even know exactly where to put our breakpoint when we debug it.
The entire process took roughly 2 hours. The only bottleneck was IDA’s analysis, as TeamViewer is a pretty large program, containing more than 143,000 functions.
Karta – How Does it Work?
Binary Matching 101
Binary matching, at its core, can be stripped down to the most basic problem: we want to check if two functions, one from a compiled open source and the other from our binary, represent the same function. To be able to compare the two functions, we need to convert them into a unified basic representation, usually called a “canonical representation.” This representation usually includes a set of features we extracted from the function: a list of numeric constants, a list of strings, the number of assembly instructions, etc.
When trying to match a group of related functions, for example, a compiled open source project,, we store additional information in the canonical representation so as to encode the relations between the functions: a list of called functions (callees), a list of functions that call us (callers), etc. Using this information, we can attempt to match two functions based on their rule / location in the Control flow Graph (CFG).
Here we use some traditional binary matching tools, such as BinDiff or Diaphora. While each matching tool has its own unique clever matching heuristics, they are all based on the same reduction: comparing two canonical representations and scoring the result. This means that binary matching tools start by converting all of the functions into their canonical representations, and continue from there.
Avoiding the Memory Blow-Up
When analyzing a binary with approximately 65,000 functions, like the firmware of our OfficeJet printer, the process of building a canonical representation for all of the functions simply doesn’t scale. It takes a very long time (usually more than an hour), and can consume more than 3GBs in disk space. Needless to say, loading this dataset to memory later on often crashes the matching program.
If we want to match anything in huge binaries, we need to change tactics. As open source libraries are relatively small, our problem can be described as:
We want to match M function in a binary of size N where M << N, ideally by consuming memory that depends on M and not on N.

Figure 5: An illustration of the binary address space in which we attempt to match our library.
Key Idea – Linker Locality
If we put aside a particular edge case that we will discuss later on, we can strip down the process of compilation and linking to the following steps:
This leads to two important conclusions:
Essentially, this is the key point that Karta is based on.
Karta – Building a Map
Karta is a source code assisted tool. By leveraging the information from the source code, we can build a map: which functions are contained in which file, and what are the files that the library consists of.
This is the procedure to match the library in the binary:
Here is an example:
All we have to do now is to build a canonical representation only for the focused functions, thus drastically improving our performance from this point onward.
Note: The map can be of further assistance, as a function foo()from file a.c should only be matched with functions from a.c. This eliminates the need to compare it with functions that we already identified as residing in different files.
Choosing Our Anchors
By their nature, anchor functions are matched before we have a canonical representation. This limits the features we can use when searching for them. In addition, we want to make sure that our anchors uniquely identify our library, and do not include any false positives to other libraries that could be in the binary we are handling.
It’s a bit ambitious to decide the criteria for complex unique features, without knowing in advance what all of the open sources look like. Nevertheless, we wrote some heuristics that seem to work well in practice. We scan all of the functions in the open source and search for unique numeric constants and unique strings. If the constants are complex enough (numbers with high entropy or long enough strings) or can be grouped together to be unique enough (for example: 3 unique medium length strings in the same function), we mark the function as an anchor.
Here is an example for an anchor function found in OpenSSL:
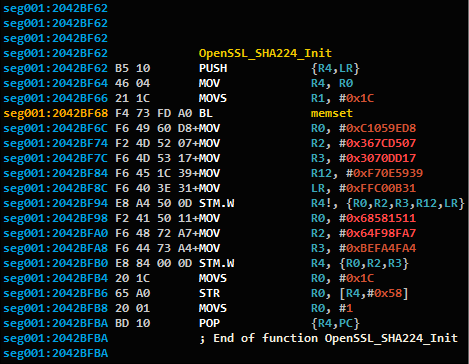 Figure 6: Function SHA224_Init from OpenSSL as seen in IDA Pro.
Figure 6: Function SHA224_Init from OpenSSL as seen in IDA Pro.
We chose this function because of its unique numeric constants.
The exact rules are configurable and can be found in this file: src/config/anchor_config.py
Matching Steps
Now that we know what is the main logic behind Karta’s matching engine, let’s list the matching steps in full.
Identifier
Every supported library has an identifier that tries to locate it inside the binary. As most open sources include unique strings, often with full version details, most identifiers are string-based and configured for the library they are trying to identify. Once the library is found, the identifier tries to extract the version information, and to fingerprint the exact version that is used by the executable / firmware.
Saying that open source projects try to hide their presence in the compiled binary can’t be further from the truth. Not only do these libraries often contain unique strings that a short Google search can identify as clues to the original library, they often contain unnecessary information. Here is an example of a copyright notice from libpng, a string that is compiled with the binary:
![]()
Figure 7: A copyright string from libpng that is included in the compiled binary.
As you can see, identifying the existence of open source libraries inside executables is relatively easy in most use cases.
While there are other solutions for the identification phase, such as the one described in Google’s Project Zero recent blog post, it seems that it is hard to compete with this basic but effective simple string search. Relying on the great results from our identifier, we decided to focus most of our efforts on the matching logic, keeping our identifier neat and simple.
Due to the simplified nature of our identifier, we hope it will be easy for other researchers to extend our plugin and to add support for new open source libraries. As it’s open source, any contribution to our plugin will help other researchers in the community with their projects as well.
Anchor Search
Using the information from the identifier, the configuration (.json based*) for the specific library version is loaded. The first step is to scan the binary for the unique numeric constants and unique strings that match the anchor functions of our library. Without an anchor, we can’t zoom-in on the library and continue the matching process.
*The entire configuration is loaded into memory once the match starts. This removes the need to use the more popular sqlite database, as we have no queries to issue on the configuration. This transition, from sqlite to json, leads to a major decrease in the size of the configuration files (KBs instead of MBs).
File Boundaries
Using the range of focused functions that was defined by the matched anchors, we draw an initial sketch of our file map. We can pinpoint the location of every file that contains a matched anchor function, and estimate its lower and upper bounds (using the same logic that was described earlier). The rest of the files are marked as “floating” and are referred to as “omnipresent”; they can be anywhere inside the overall focus area.
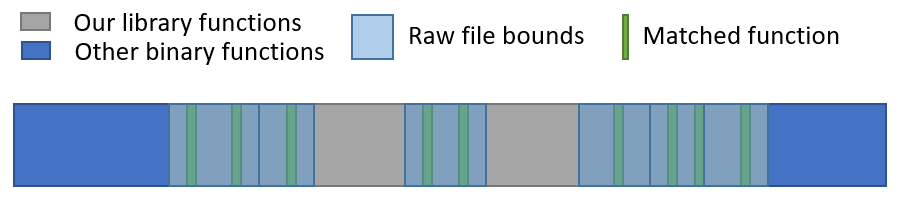
Figure 8: An example map of our matching results so far.
Using File Hints
Many open source projects tend to include debug / trace strings that contain the names of the source files. Usually these strings are located in functions from the mentioned source file, which means we can use them as file hints. After drawing the initial map, we can use these hints to pinpoint the location of additional files. Relying on the fact that the search space is quite small, and on the nature of those strings, these matches will have relatively high True Positive ratios.
Locating Agents
An agent is a locally unique function. It can also be referred to as a local anchor. Within its file it is an anchor, but the constants it contains are weaker than those required from a global anchor. Each located file tries to match its own agents, again with relatively high True Positive ratios.
Matching Rounds
From this point on, our logic is quite traditional. Every match attempt is given a score, based on the similarities of the two canonical representations. The matching ends when there are no more functions to match (optimistic scenario), or when the matching round fails to find new matches, or when an inner file identifies that an inner assumption fails to hold. The latter case often happens when IDA has an analysis problem, or when there are linker optimizations (see next chapter).
As mentioned previously, Karta attempts to use as much geographical knowledge as it can, including:
Each of these location-based heuristics has been shown to significantly improve the matching results in real case scenarios. A full list of matching heuristic tips can be found in Karta’s read-the-docs documentation, accessible from our Github repository.
Linker Optimizations
Until this point, we chose to ignore the elephant in the room: Karta’s main assumptions are that the open source will be compiled as a single contiguous blob, and that the inner files are not mixed up with one another. Unfortunately, this isn’t the case when compiling with linker optimizations, as is already being done when using Visual studio to compile Windows programs.
Indeed, when we initially attempted to match libtiff in one of Adobe PDF’s binaries (2d.x3d), we had less than optimal results: only 176 / 500 functions were matched. After a brief investigation, it seemed that the linker combines functions with the same binary structure. For example, a function that was implemented twice with different names or in different name scopes (static functions from different files).
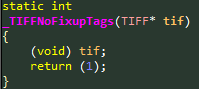
Figure 9a: First of two identical functions from libtiff that reside in different files.
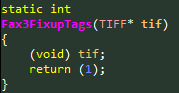
Figure 9b: Second of two identical functions from libtiff that reside in different files.
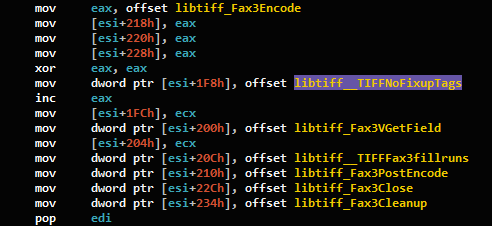
Figure 10: Analysis from IDA Pro, showing that the upper function is used instead of the lower one.
While this optimization reduces the size of the executable, it not only messes with our locality assumptions, it also drastically changes the control flow graph. Two unrelated functions, each with its own edges, will be merged into a single vertex in the call graph. Several quick checks later, we found that this optimization damages the matching results of other binary matching tools as well.
We decided to tackle this issue just like the linker does. When compiling the canonical representation for the open source library, we hash the linker’s view* of each function, and store it as a unique function ID. *Initially we hashed the bytes themselves, but that introduced a bug when two functions refer to the same global variable and that variable resides in different offsets in each file. See Figure 11 and 12. We solved this issue by hashing the bytes for most opcodes, and hashing the text of the instruction when referring to an exported global variable.
Figure 11: Function TIFFClampDoubleToFloat()from the file tif_dirwrite.c.
Figure 12: Function TIFFClampDoubleToFloat()from the file tif_dir.c.
Our matcher uses these “collision IDs” to define groups of potential merge candidates that the linker might decide to merge together. During the matching process, the matcher looks for clues of any possible merge. When the matcher finds in the control flow graph signals that two merge candidate functions are possible candidates for the same binary function, it can decide that a merge occurred. Upon making this decision, the binary function now knows that it represents several source functions, and will hold a list of the merged source functions that it matched.
Using this optimization, we can now fix back anomalies in the control flow graph, as each detected merge effectively expands the control flow graph one step back to its original state before the linker optimizations. When tested again on the same binary (2d.x3d), we had significantly better results: 248 / 500 functions were matched, an improvement of 41 percent.
As we can see, Karta identified the linker’s optimizations for the function _TIFFNoFixupTags:

Figure 13: Matching results from Karta that successfully identify linker-merged functions.
Matching Results
It is time to test how Karta handles our original OfficeJet firmware. We tested the plugin inside a virtual machine (VM) on our computer (not an optimal benchmarking environment), and here are the results:
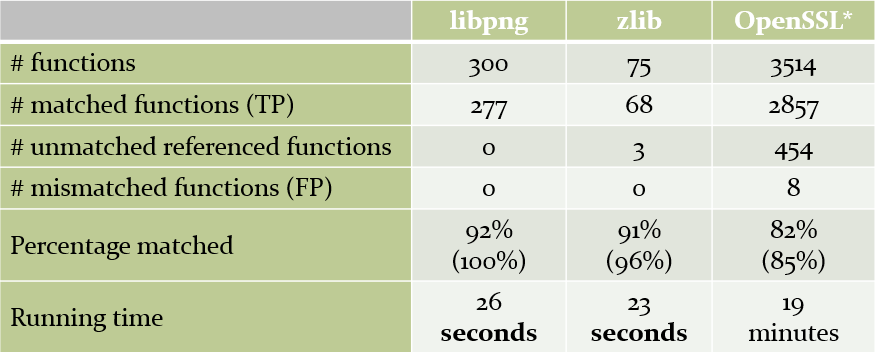
Figure 14: Matching results on our tested OfficeJet firmware.
As we can easily see, even with approximately 65,000 functions, it took less than 30 seconds to match an open source with 300 functions such as libpng. In addition, we were able to match all of the referenced library functions, i.e. functions that have at least one edge in the control flow graph.
*The only way to verify the results was to perform a manual analysis of the functions in IDA**. As OpenSSL contains an insane amount of functions (for an open source), the False Positive ratio could be higher, as we didn’t manually analyze all of its functions.
**Actually, Karta proved to be more accurate than our manual analysis, as on most conflicts it turned out that we were wrong and Karta did a better job labelling the function.
Note #1: It is important to note that as Karta works on the canonical representation of the functions, it is architecture agnostic. The configurations we used for the above comparison were compiled using gcc on an x86 32-bit setup, and were later matched to a Big-Endian ARM Thumb mode binary.
Note #2: Because our matching is done from the viewpoint of the matched open source library, we can also deduce information on “external” functions – functions that aren’t part of our library, but are called from it. For example, libpng uses zlib, so our matcher was also able to identify the inflateEnd and deflateEnd functions even before it started matching zlib.

Figure 15: External zlib functions matched during libpng’s matching.
In addition, in most cases we were able to match functions from the standard library such as: memcpy, memcmp, malloc, etc. Any researcher that works on reversing firmware files knows that the lack of FLIRT signatures makes it mandatory to start each project by reversing and matching the popular libc functions. By using Karta, most of the popular functions will be matched “for free”, saving us the need to figure out which function is memcpy and which is memmove.
Comparison to Known Bin-Diffing Tools
We are aware that it is sometimes hard to differentiate between all of the available binary diffing / matching tools. Now that we’ve finished presenting Karta, it is a good time to compare our plugin to other popular tools, focusing on the different goals and characteristics of each tool. Keep in mind that we don’t benchmark the results of the tools, mainly because these tools weren’t designed for the same goal.
As we couldn’t compare all of the existing tools out there, we chose to focus on the following popular tools:
BinDiff: “BinDiff is a comparison tool for binary files, that assists vulnerability researchers and engineers to quickly find differences and similarities in disassembled code.
With BinDiff you can identify and isolate fixes for vulnerabilities in vendor-supplied patches. You can also port symbols and comments between disassemblies of multiple versions of the same binary or use BinDiff to gather evidence for code theft or patent infringement.”
Diaphora: “Diaphora (διαφορά, Greek for ‘difference’) is a program diffing plugin for IDA, similar to Zynamics Bindiff or other FOSS counterparts like YaDiff, DarunGrim, TurboDiff, etc… It was released during SyScan 2015.”
Pigaios: “Pigaios (‘πηγαίος’, Greek for ‘source’ as in ‘source code’) is a tool for diffing/matching source codes directly against binaries. The idea is to point a tool to a code base, regardless of it being compilable or not (for example, partial source code or source code for platforms not at your hand), extract information from that code base and, then, import in an IDA database function names (symbols), structures and enumerations.”
FunctionSimSearch: FunctionSimSearch is a set of tools to efficiently perform a fuzzy search into a relatively large space of possible functions (the binary). The goal of these tools is to match known (possibly vulnerable) functions in order to identify statically linked software libraries*.
*Project Zero’s didn’t explicitly define a summary of FunctionSimSearch. This is our description, not a quote from their site.
Karta (our plugin): “Karta (Russian for “map”) is an IDA Python plugin that identifies and matches open-sourced libraries in a given binary. The plugin uses a unique technique that enables it to support huge binaries (>200,000 functions), with almost no impact on the overall performance.”
The comparison parameters are:
Here is the table with our results:
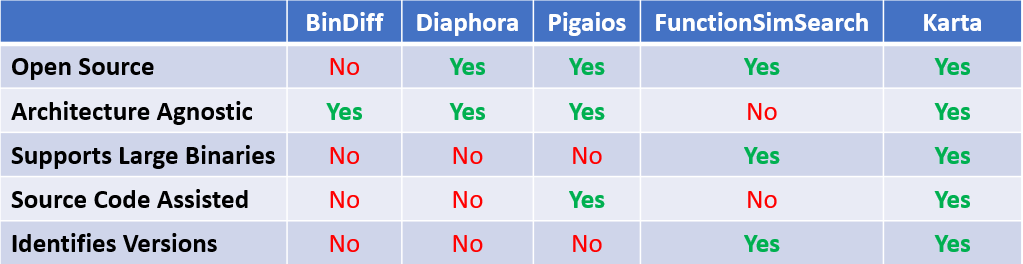
Figure 16: Comparison between our matching tool, and popular diffing / matching tools.
Note: Although BinDiff and Diaphora can be used to compare (bin-diff) two binaries, for example, for patch diffing, Karta was developed with the goal of matching binary symbols of known open sources. While this limits the use cases for which Karta can be used, its focused goals enables it to achieve improved matching ratios using simpler comparison heuristics.
As there is no (known) silver bullet to solve all binary matching / diffing problems, we believe that it is important to judge each tool based on the goals for which it was first designed.
Appendix A –list of currently supported identifiers






