The Blitz Tutorial Lab on Fuzzing with AFL++
March 6, 2023

To paraphrase a famous quote by Pete Cordell, telling an infosec enthusiast there’s already a tutorial on how to do X is like telling a songwriter there’s already a song about love. This specific tutorial is borne out of sympathy for readers who know their way around C language, GNU make and the like, but upon seeing the word “fuzzing” have muttered to themselves some variation on “meh, that sounds complicated”. The guiding principle in this tutorial is minimalism in the requirements: carrying the reader to “hey I fuzzed a program and found a bug” with the least possible amount of work.
To this end, the tutorial uses a lab format we’ve encountered a few times ‘in the wild’ and found to be very effective — a series of exercises where every possible bit of boilerplate has already been filled in, and the reader must only complete the load-bearing logic; and, in the event the correct solution still proves elusive, a complete solution is available that can be compiled, run and seen to achieve the desired effect. The reader can thus freely choose to what degree they want to engage with the material, on the spectrum between “not at all” and “excessively”. By this we mean it is possible to complete this lab by repeatedly copying, pasting and hitting return; and, conversely, it is possible to take a deep dive and understand each solution enough to write it from scratch or tinker with it.
As a fuzzing target this lab uses an old version of libtiff, a library for reading and writing TIFF format files. TIFF is a format for storing raster graphics images, popular among graphic artists, the publishing industry, and photographers.
A git repository of the exercise files is available here. If your instinctive response to that is “ugh” then do not fret, every time you need a file for one of the exercises, a direct link will be provided for you to download the file. Of course, if your instinctive response is “yeah yeah ‘git clone’ I know the drill” then you know what to do.
You will need a Linux machine — the commands listed assume Ubuntu; if you are using something else, adjust accordingly. You will also want to keep on-hand the libtiff documentation for basic file handling.
We will now participate in the time-honored tradition of the sanity check, the importance of which we really cannot overstate. No one likes to spend an hour isolating the exact cause the fridge won’t turn on in the midst of a power outage — but somehow it seems every developer has at one time been reduced to essentially doing this (e.g. adding 7 increasingly banal printfs to some code before finally realizing they were editing the wrong file). If and when we run into an issue later, we want to make sure that the issue is in fact the actual material, and not something down the stack that prevents us from even properly compiling and running a program that makes simple use of libtiff in the first place.
First, we must obtain a copy of the obsolete version 4.0.6 of libtiff. Perform the following steps:
cd /usr/srcsudo wget https://github.com/vadz/libtiff/archive/Release-v4-0-6.zipsudo unzip Release-v4-0-6.zipsudo chown -R <your_user_here> libtiff-Release-v4-0-6cd libtiff-Release-v4-0-6/./configure i686-pc-linux-gnu CFLAGS='-m32 -g' CXXFLAGS='-m32 -g'make clean (in case you have leftover object files from previous build)makeYou also want to execute the command mv ./libtiff/mkg3states.o ./libtiff/mkg3states.o.bkp. This wart is due to the file mkg3states.o having a main function; we want to create our own program that will have its own main function, and so getting the file out of the way is necessary to prevent a conflict during the compilation process.
Unless you’ve seen it before, the below is your first introduction to the boilerplate-included exercise format we’ve mentioned in the introduction. Below you are given two files: loadtiff.c and Makefile, and you are required to fill in the blanks, which are numbered #1, #2 and so on. It so happens that in this specific exercise there are no blanks to be filled for Makefile — it can be used as-is.
To solve the exercise, make the necessary modifications to loadtiff.c: that is, add the correct path to the file tiffio.h and then the invocations of the functions TIFFOpen and TIFFClose where they are missing (you will have to consult the libtiff documentation to understand how to do this). Then run make loadtiff. Once compilation succeeds, run the loadtiff executable on the file brain.tif (available in the samples directory of the git repository, here). This is done by simply running ./loadtiff /path/to/brain.tif. Verify that you get the output message TIFF load successful!.
If you have successfully run loadtiff on an input TIFF file and received the message TIFF load successful! then you have cleared the sanity check: that is, you can compile a simple program that makes use of libtiff’s facilities for reading and manipulating TIFF files. Without reaching this milestone there is little point in attempting the other exercises.
The good news is that there is nothing to solve in this exercise. It is a repeat of exercise 0 with one additional terminal command, which is provided to you in its entirety. The bad news is that to get to that part, we lead with several paragraphs explaining what this one additional terminal command does, a la Charles Steinmetz’s famous $10,000 chalk mark.
Fuzzing is an easy concept, but is not so easy to implement. It involves feeding a program different inputs and observing if and how its execution path changes. The task can be explained to a five-year-old, but how would you explain it to a computer? “Take this program, and whenever you see an if statement, you should — ” but there is no API that can elegantly engage with the problem on that level. The foundation isn’t there. This is a, how do they call it, “Semantic Gap”.
AFL++ (American Fuzzy Lop plus plus) solves the above conundrum the hard way. It reads the program source and painstakingly assembles a meta-program that supports running the original program again and again, trying various inputs, and reacting based on the original program behavior. Therefore, from a certain point of view, AFL++ is a compiler — one that, it should be clear now, abstracts away a truly enormous amount of developer suffering. Appropriately, then, AFL++ is implemented as a drop-in replacement for gcc.
Under the hood, AFL++ uses a genetic approach to generating program inputs; this means that inputs that caused the program to reach a novel state of execution are used as a baseline when trying to find further such inputs, by introducing partially random perturbations which are chosen with some thought (what if we pretend this byte is an integer, and add 1? What if we pretend it is a bitmask, and perform a logical not operation? And so on).
ASAN stands for “address sanitizer” and it’s an open source programming tool by Google that detects memory corruption bugs such as buffer overflows or accesses to a dangling pointer (use-after-free). Similarly to AFL++, it intercedes during the compilation process; but as opposed to AFL++ which changes the whole nature of the program, ASAN mainly makes the experience of running into memory corruption bugs cozier. You’ve surely seen a C program produce an access violation (“segmentation fault”) — indeed, the early stages of learning C language involve an intense effort of getting a program to do anything else — and what ASAN does is temper this experience with some context and colorful output. Programs compiled with ASAN will produce pretty-prints and detailed diagnostics when they encounter a memory management error. While this is not strictly necessary for finding bugs, it is very helpful when triaging them and trying to understand their root cause. Unless the drunk random walk of inputs produced by AFL++ magically produces a fully-formed exploit (spoiler: this is unlikely), chances are you will first run into a bug in the form of the original program violently dying, and ASAN will help you get the investigation started.
Let’s compile a new version of libtiff with AFL++, with the ASAN flag set. The easiest way to coerce the project to do this for us instead of using vanilla gcc is by using the configure command. Perform the following steps:
sudo apt install afl++libtiff-Release-v4-0-6 directory and do:make clean (in case you have leftover object files from previous build)makecd /usr/src/libtiff-Release-v4-0-6/libtiffmv mkg3states.o mkg3states.o.bkp (again)./configure i686-pc-linux-gnu CC=afl-gcc CXX=afl-g++ CFLAGS="-lasan -fsanitize=address -m32 -g -O2" CXXFLAGS="-lasan -fsanitize=address -m32 -g -O2"afl-gcc instead of gcc, and use the correct flags to invoke ASAN during compilation (as well as some more prosaic settings, such as declaring a certain machine code optimization level and asking for 32-bit output).Now, go back to your code from exercise 0, compile and run it again. Verify that you get the message TIFF load successful! again.

There is one final obstacle that needs to be cleared before we can perform an actual fuzz: the program we have written, loadtiff, is not actually the right shape to be used by AFL++. When AFL++ performs fuzzing, it takes candidate inputs and feeds them to the fuzzed program via the standard input. You’ll note that so far our loadtiff has taken its input in the form of a file, with the file name provided to the program as an argument; we have to rectify that. Also, we are going to dip our feet into doing something slightly less trivial with the libtiff API itself, so that we get used to the idea of using the API to interact with a TIFF image rather than just loading it into memory as a TIFF object. These two steps forward are completely orthogonal to each other, we could do just one without the other.
We’ve set the bar to clear for “interacting with the image in a slightly less trivial way” to be the most straightforward we can think of: printing the image’s width and height (henceforth “length”, because that’s the terminology libtiff uses). This simple task still requires consulting the libtiff API documentation and understanding how to use it, a basic skill without which the exercise after this one would probably be biting off more than we can chew. Also, if need be, this is your chance to read the solution and get the hang of using the API to do more than just load an object, without spoiling the whole solution for the next exercise where we perform an actual fuzz.
loadtiff.c.
BUF_SIZE from the standard input and write the read bytes to the temp file. You have already been given BUF_SIZE and a pointer to the temp file.TIFFGetField to obtain the resulting TIFF object’s width and length, and populate the aptly-named variables width and length. You will need to consult the documentation for the TIFFGetField function to see how to do this.make loadtiff../loadtiff < ../samples/brain.tif and verify that the image width and length are printed.
That’s it, we’re ready to actually run AFL++. In this exercise we will learn how to invoke afl-fuzz, which sets off the actual fuzzing process. Also, instead of just printing the image width and length, we will give the fuzzer something more substantial to chew on: parsing a TIFF image and converting it into a different format.
Why all this busywork? Couldn’t we have just focused on running afl-fuzz? Well, yes, technically we could have. But think about what our current version of loadtiff does; it loads a given TIFF image and prints two properties that are stored neatly in the image header. Now recall that the goal of this entire process is to find bugs — that is, the program failing in some nontrivial way to do what it set out to do. How can the program fail at reading some bytes out of a header? Very barely. Maybe the header says something nonsensical, like the length of the image is a negative 7 pixels, so the program dutifully prints that information; that’s not a bug, it’s a party trick for a junior high LAN party, and we’re being generous. afl-fuzz can test inputs on the program from exercise 2 for months without encountering a single fatal error, and that’s not a useful result. To put it in concise Cochran form: If the program won’t crash, ctrl+C back to bash.
You know you have finished the exercise when you are looking at the AFL++ status display and new crashes appear occasionally, but not constantly. If new crashes appear constantly chances are there is a serious bug in loadtiff.c itself, rather than libtiff. Theoretically speaking, if crashes do not appear at all, then either the harness does not invoke the library logic in an invasive enough fashion, or else none of the bugs in the library are of the sort a fuzzer will find (or maybe the program being analyzed has no bugs, but it is a known result in empirical computer science that there are no such programs). We’ve picked an old version of libtiff to rid you of this consideration: there are definitely bugs that the above harness can find, once completed, and the first one will probably pop up within a few minutes.
The exercise itself is comprised of two main tasks. The first is adding a fuzz item to the makefile that will invoke the correct command line to launch afl-fuzz and begin the fuzzing process. This also requires setting up the input and output directories; the input directory should be the samples directory (download it from the lab’s git repository here if you don’t have it), and afl-fuzz needs to be explicitly told to use it as the input directory. The output directory should be an empty directory named out. Also, the exercise calls for limiting the memory used by afl-fuzz to 900MB. Consult the documentation of afl-fuzz in order to understand how do this properly.
The second task is modifying loadtiff.c to convert the input TIFF image to an RGB raster — an action that actually requires meaningfully parsing and evaluating TIFF logic, and might lead to the program mishandling input. This requires correctly setting the value of a variable named raster_size that controls the size of the allocated RGB raster, As well as correctly using the libtiff API functions TIFFRGBAImageBegin, TIFFRGBAImageGet, and TIFFRGBAImageEnd. Consult the documentation of these functions to understand how to invoke them correctly.
Once you’ve done all that you can run make fuzz and check the crashes directory for some choice inputs that supposedly make loadtiff crash. Test the crash by feeding it into loadtiff as input.
To complete the exercise:
Makefile and loadtiff.c.make loadtiff.samples directory, and ensure the command line in Makefile that invokes afl-fuzz names it as the input directory.mkdir out — you will need this directory later.make fuzz.qterminal when our gnome-terminal color scheme didn’t play well with afl-fuzz).tiff_to_rgb < ./out/crashes/pick_your_favorite_file_from_here.IMPORTANT!: If you are still not getting any crashes even if you copy-paste the given solution, and suspect that the issue is the exec speed, you can go directly to the next exercise to verify your suspicion.
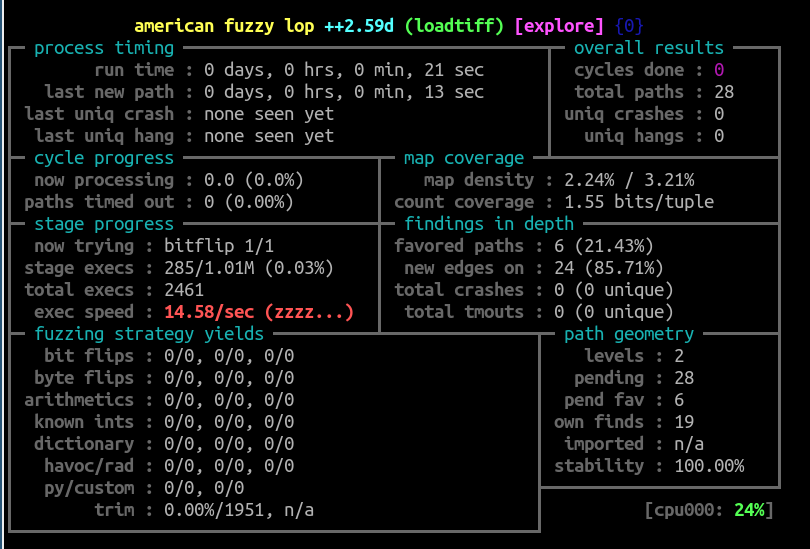
We could have stopped at exercise 3, but that’d be doing you a disservice. If you look closely enough at the afl-fuzz display panel, you may notice that a few seconds into the fuzzing, the exec speed sees a major drop – to the double and single digits. Running a program 15 times a second can barely be called “fuzzing”, and AFL++ even chastises us with a red (zzzz...) next to that statistic.
What can we do? Several things:
afl-gotcpu to see whether you have enough resources to launch additional fuzzers in parallel.There’s one thorny issue, though — the code we wrote doesn’t support parallelism! It converts the TIFF given to it via standard input to a file, but that file name is the same for every running instance of the program. If we run several instances in parallel, they will step all over each other and we will get very unpredictable results (this is reflected in the “stability” metric dropping dramatically; when all is well, in this deterministic program stability should be 100%.) Since every output file lives for a very short amount of time, and we can live with the very rare collision, for our purposes it is enough to introduce some quick and dirty randomization to the output file name by appending some random characters to it.
The below exercise is about implementing some of the changes described above. First, you should create a prepare_samples makefile item that sifts through the TIFF images in the samples directory and deletes all files larger than a certain threshold (the sweet spot during our own tests seemed to be 1KB). Second, you should create a fuzz makefile item, that now instead of running the single-instance serial afl-fuzz, runs afl-fuzz in parallel mode; this requires several commands, and you will have to consult the AFL++ documentation to understand how to do it.
As for loadtiff.c, in this exercise the one modification to it is adding support for randomized output file names. This involves reading pseudorandom bytes from /dev/urandom and using them to pseudorandomly pad the output file names with some well-behaved printable characters.
To complete this exercise
Makefile and loadtiff.c}.make loadtiff.mkdir out — you will need this directory later.make fuzz.afl-fuzz and verify the improvement in exec speed.afl-whatsup ./out and observe the output../loadtiff < ./out/crashes/pick_your_favorite_file_from_here.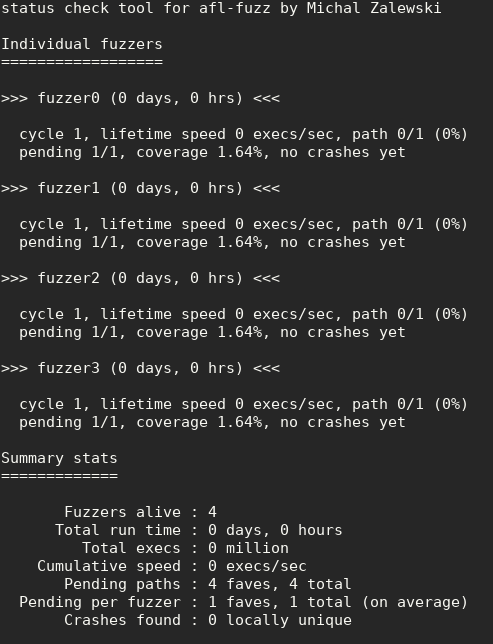
Fuzzing enjoys a somewhat notorious reputation as a bug finding technique for people who aren’t hardcore enough to squint at disassembly and manually fish out a use-after-free. We recall reading a succinct and relatable social media post that said, more or less: “I spend hours sifting through a program to find a bug only to hear that, using the same time investment, some idiot with a fuzzer just found 50”. Well, congratulations: now you, too, can be that idiot with a fuzzer! In all seriousness, automation is the future, and the real question should be how to make fuzzers also find the one bug that AFL++ could not find, and that required a trained human eye to tease out. If you liked toying with AFL++, you might want to look into tools that reach for that goal, and try to push the boundaries of how clever the “clever guessing” can get when mutating inputs — such as Eclipser and Driller.
Our special thanks go to Eyal Itkin for his technical advisory of this project.






