Thumbs Up: Using Machine Learning to Improve IDA’s Analysis
June 24, 2019

Research by: Eyal Itkin
Introduction
At the beginning of 2019, we released Karta, a plugin for the IDA disassembler that identifies open sources in binaries. During our work on the plugin, we stumbled on a gap between theory and reality: Karta’s accuracy depends heavily on the quality of the function analysis performed by the disassembler. And that analysis, especially when dealing with firmware files, is far from perfect. As manually improving the analysis would be a long and onerous task, we chose instead to try using an additional script. This time we also decided to throw in a bit of Machine Learning and see if it helps. Surprisingly, it did.
Thumbs Up is an IDA plugin to enhance the function analysis of the disassembler, and is meant to be used in a pre-process phase before using Karta. As its name suggests, the plugin also drastically improves the transitions between Arm and Thumb code parts in an Arm binary.
Attempt #1 – Rules of Thumb
In our first attempt to implement the plugin, we borrowed a number of lessons from the reverse engineering trade and tried to merge them all together. The result was a huge pile of rules-of-thumb that were activated one after the other. The code scans were line-based:
And so on.
Although these rules resulted in major improvement, the final result still wasn’t good enough. Something was missing, and it simply felt wrong to accumulate so many specific rules. We knew there must be a better way to reach our goal. However, with no clue as to how to continue with our plugin, we left it aside temporarily, and came back to it a few months later when we published Karta.
In this second attempt, we tried a new approach: could Machine Learning do a better job of analyzing some of the features in the program? After all, it should be better than us in merging many if/else cases together.

We quickly developed a small proof-of-concept (PoC) for identifying functions’ prologues and epilogues using a simple Random-Forest classifier. The initial results were staggering: 97% accuracy for identifying Thumb functions in our test OfficeJet firmware (leftover from the FAX research). After seeing our PoC succeed beyond our expectations, we decided to base our plugin on these classifiers and see if this time the plugin would achieve the desired results.
Attempt #2 – Identifying Features
We defined several tests for our plugin, keeping in mind that it should be used as a pre-process phase before using Karta. The tests:
![]()
Figure 1: IDA’s initial analysis results for the OfficeJet firmware.
The numbers for our first, and primary, test case:
Code Features
From the Machine Learning PoC, we learned that instead of analyzing the binary line-by-line, we could focus on code features instead. And more specifically, a simple Random-Forest classifier could easily predict if the following bytes matched the prologue of a function. While playing with the feature set that was used to train the function classifier, we learned some important lessons.
Using Bytes
Initially, the feature set consisted of the names of the assembly instructions at the start of the function. This was problematic, as in some cases we wanted to check if a given data chunk was actually a prologue of a given function. In addition, the Python library didn’t cope well with using strings for the feature set, so we had to define an ugly workaround for encoding them as numbers.
Having no background in Machine Learning, we talked with more experienced researchers who advised us to use the simplest feature set we could manage and that still works. Therefore, we chose to use bytes instead of assembly instructions, which solved both of our problems. Surprisingly, using the bytes improved our accuracy, which proved it was the right choice.
Using the right bytes
Having no good measure to begin with, we initially defined the size of our feature set to be 14. We had no specific reason to pick this exact number, but it sounded large enough. The first 14 bytes in a function are the feature set for its prologue, and the last 14 bytes are used for the epilogue. Actually, we started by taking the bytes at offsets [-4, 10] for the prologue, which turned out to predict a function’s start if it saw the epilogue of the previous function. While that usually worked, it wasn’t the expected behavior and it did damage our results in some edge cases. This led us to keep a clear separation between the prologue and the epilogue of a function.
While the performance was pretty good, we remembered the advice we received earlier and tried to shorten the feature set. Being human, we couldn’t simply look at the bytes and decide out of the blue what are the “right” ones to use, so we simply asked the classifier:
This small modification has several advantages:
Machine Learning is not a silver bullet
The basic Machine Learning classifiers worked like magic for identifying functions, and it was time to see if they could solve the rest of our problems as well. An important code feature in the OfficeJet firmware is switch tables. The tables are generated by the compiler to work as an efficient lookup-based replacement for if/else chains. An example is shown in figure 2.
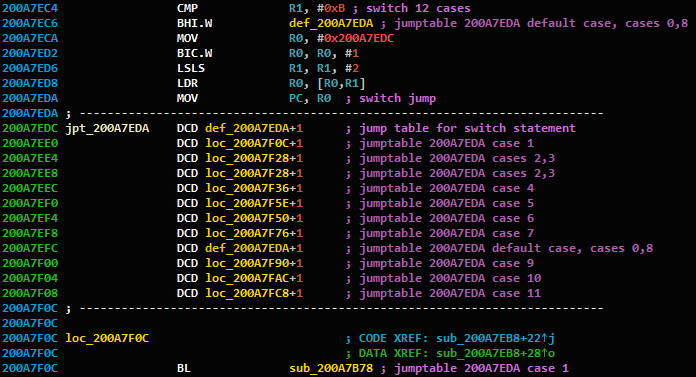
Figure 2: An example switch-case table inside a code function.
An important thing to note is that these tables are placed inside our functions. If we miss these tables during our analysis, we might accidently treat them as code, thus significantly damaging the analysis.
Although we tried to train a classifier to detect such tables, all our attempts failed. It could be that since IDA only found 122 such tables to begin with, we simply didn’t have a large enough data set. Or, maybe we simply didn’t pick the right features to be used in this case. At any rate, we learned a valuable lesson: Machine Learning isn’t a silver bullet that will solve all of our problems. The best solution is probably a hybrid one:
List of Features
Using the Arm firmware for our first test case proved useful, as this was the most complex test, and it covered all of the features we needed for the rest of the tests as well. The overall list of code features we identified is:
As the Machine Learning-based classifiers only worked for identifying functions, we used “pattern observers” for some of the other features.
Pattern Observers
One important architecture feature is code/data alignment. For example, in a 32-bit ARM architecture, all referenced in-code numeric and string constants are aligned to 4 bytes. See the example in figure 3.

Figure 3: In-code constants stored after the function, each aligned to 4-bytes.
Instead of hard-coding this alignment for every architecture and code feature, we defined an “alignment observer.” The observer is trained on all of the IDA recognized features of a specific type. Using only some arithmetic voodoo (the GCD algorithm), it outputs the alignment of the code feature.
For the switch-case tables we had to use an additional observer. Using the alignment observer, we identified that the tables themselves are aligned to 4-bytes, and we need to check for a unique code pattern before each table. For this purpose, we defined the “pattern observer” that checks for a common code pattern:
If we go back to the previously seen switch-case figure, we can see that there is a unique code instruction before the table, as is circled in figure 4.

Figure 4: Every switch-case uses “MOV PC, __” for the jump instruction.
On top of these two observers, we added one more basic heuristic that makes sure that the followed aligned table indeed contains valid code pointers to the nearby located code. After we combined it all together, we ran our script again and crossed our fingers in hope that this time it would identify the switch tables correctly. Not only did this work, the results were staggering: IDA initially identified 122 switch-tables and our switch identifier located more than 600 such tables. We found 5 times more switch tables than IDA!
Function Pointers
Function pointers are an important feature for the program analysis – they tell us the whereabouts of a function, usually it’s an important one. While it is hard to distinguish between an arbitrary data constant and a function pointer, it really shouldn’t be that hard. What is a function pointer after all?
Looking back at these two questions, we can see that we already collected enough tools to answer both of them:
On top of this logic, we added an additional layer that embeds an important reverse engineering lesson: the data segment tends to contain arrays of records of a given structure. If we find enough function pointers that are evenly distanced from each other, we might locate such an array. An example of this type of array is shown in figure 5.
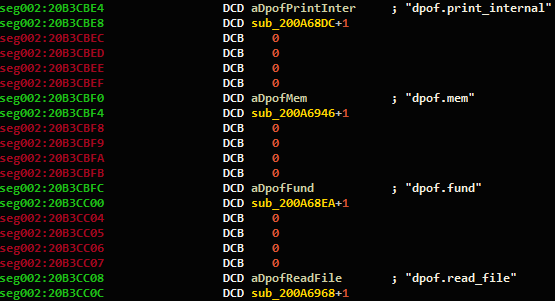
Figure 5: An example struct array that contains function pointers.
After we finished implementing the described logic, we had a test run on the OfficeJet firmware file and it found more than 19,000 function pointers. And remember, we had only roughly 40,000 functions to begin with.
Thumbs Up
As we mentioned earlier, one of the goals of our plugin is to improve the distinction between Arm and Thumb code parts. This task consists of two parts:
In our tests, it seemed that the first part is the dominant one, as we found many fake small code regions. Once again, we defined the expected characteristics for each code type region:
And so on.
In addition, several code regions were created because of falsely declared function pointers. This makes sense, because even if our Machine Learning classifier has an accuracy of 97%, it still means that out of the 19,000 declared function pointers there will be several false positives. If we identify a false code region, and it starts with a function pointer we declared, we remove that function pointer as well. It is important to admit mistakes when we recognize them.
For the second part, we used the code-type classifier. If we found an unexplored chunk/unreferenced data chunk, and the classifier declared it started with the prologue of a function from a different code type, we then declared a code transition and declared the function. This phase was only activated after we finished most of the analysis, as it is rather aggressive when compared to other heuristics we deployed.
Functions and Xrefs
Traditionally, IDA won’t declare a code chunk as a function if it has no references to it (a.k.a xrefs). In figure 6 we can see an example from a Mips program.
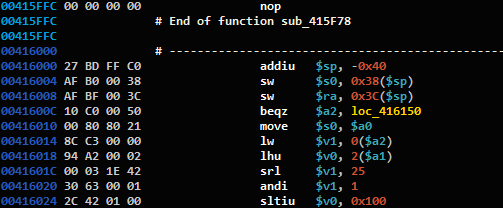
Figure 6: Unrecognized Mips function, right after a recognized one.
This is a sensitive point, as Karta heavily relies on this exact analysis. Karta only works on identified functions, and if we don’t declare them as such, it might think that the file contains fewer functions than it should.
We addressed this issue using two code passes. In the “simple” pass, we declared as functions everything that looked like a function start and that was found after a function/data chunk. In the “aggressive” pass, we declared everything that remained, and so might have introduced false positives. One way to fix those falsely declared functions was combined into the function chunk fixing logic.

Figure 7: An example function chunk that is contained inside a different function.
Figure 7 shows an example of an analysis error, in which a function “swallowed” additional functions/code chunks. From our experience, in many cases this is the result of trying to overcome compiler tail-call optimizations. Happily for us, most of these cases are easily fixed using simple connectivity groups analysis in the function’s basic block graph.
Results
Arm Big Endian – OfficeJet Firmware
As can be seen in figures 8 and 9, Thumbs Up was able to drastically enhance IDA’s analysis after training on the same features that IDA initially recognized.
![]()
Figure 8: IDA’s initial analysis results for the OfficeJet firmware.
![]()
Figure 9: IDA’s analysis for the OfficeJet firmware, after using Thumbs Up.
In numbers:
We also received similar results for the rest of our binaries.
Arm Little Endian firmware:
Mips ELF file:
Disclaimer
Although we were quite satisfied with the results on our small test set of firmware files, we can’t objectively say that the results will always be the same for every firmware file. Since we don’t have a data set with hundreds of properly selected files, we chose to open source our tool and let the research community test it on actual test cases. Hopefully the feedback from the research community will enable us to further improve our tool so that it will be of better benefit to all.
Testing Karta
And now for the moment of truth: testing Karta on the OfficeJet firmware and comparing the results to the ones we had after manually analyzing the firmware. Figure 10 shows the results of using Karta in both cases:

Figure 10: Karta’s matching results on both analysis methods.
Just for the sake of comparison, using Karta on the initial OfficeJet firmware produced 118 matches for libpng, and then Karta stopped because one of its assumptions broke.
These results clearly show that although not perfect, Thumbs Up successfully enhances IDA’s analysis to a level in which Karta can be used to achieve near optimal results (96% when compared to the manual analysis).
Conclusion
Thumbs Up is a test case which shows that basic Machine Learning classifiers (in our case, Random-Forest) can be used to learn program-specific features, and also to improve the analysis for the same program. Although we initially feared that the results would only be valid for firmware files of a large enough size, the Mips example shows how a small program with 2500 functions can still benefit from this approach, reaching a classifier accuracy of more than 96%.
In conclusion, we highly recommend that researchers use Thumbs Up to groom their *.idb files before they start their research. The plugin proved itself useful as a pre-process phase allowing researchers to use Karta without manually improving IDA’s analysis.






