Cuckoo SandBox on AWS
March 11, 2019

Cuckoo Sandbox: An Introduction
From software vulnerabilities to APT groups, there are many areas of cyber research that Check Point Research is involved with. Arguably, one of the most challenging areas of research, though, is malware analysis.
Of course, various tools are available to help with these often challenging investigations, one of them being Cuckoo Sandbox, an open-source system that can automatically emulate files on separate Virtual Machines (VMs).
The general result of using Cuckoo Sandbox is that it collects various measurements from the malware and runs an analysis which is then presented as a detailed report. Our main focus in using such a tool is to understand the malware’s behavior and measure the effect it has on a victim’s machine.
Currently, the Cuckoo system has only had integrations (AKA Machineries) for several traditional VM frameworks such as VirtualBox and VMware. Indeed, while running a Cloud VM would often be superior over a traditional VM, Cuckoo’s official code unfortunately does not include any implementation for a cloud-based environment.
Not satisfied with this situation, we began coding and can now introduce a version of Cuckoo Sandbox for the cloud.
Cuckoo Adaptation to the Cloud
Adapting Cuckoo Sandbox to the cloud has many advantages:
The most significant benefit, though, is the ability to instantly scale up or down as needed.
Imagine an almost limitless number of parallel machines with no performance implications. This could, for example, be beneficial within a system of multiples requesting simultaneous analysis of the same of different malware and makes Cuckoo-in-the-Cloud a game changer.
As the official Cuckoo repository does not include any cloud support, we started searching for any community implementation of the Cuckoo machinery in a cloud environment. Eventually, we spotted a response from one of the original Cuckoo developers to an inquiry regarding “Control AWS [Amazon Web Services] EC2 instances”:
“If you’re interested to develop the module to work with AWS, in particular the new i3.metal thing, we could consider this. Otherwise for now I’ll be closing this issue as we don’t have much interest in implementing it (Cuckoo works just fine on a bare metal machine anyway). Thanks!”
We decided to take the challenge!
Terminology
Before we continue, as this is about to get technical, let’s define some terms:
Guests – Sandbox machines to run an analysis on.
Nest – The main server that controls and collects data from guests.
Machinery – A Python layer that allows the nest to control physical/VM guests.
(Note: Different types of VM environments must use their complementary Machinery)
EC2 Instance – A Virtual Machine in AWS.
Volume – An AWS EBS [Elastic Block Storage] volume. The volume is a virtual hard drive that can be attached to a single EC2 instance.
Goals
Our objective was to develop Cuckoo extensions to meet the following demands:
Initial Design
Our first step was to create an API wrapper for EC2 basic actions so we could align the EC2 handling with other Cuckoo supported VM frameworks.
For example, unlike traditional VM API, the AWS API only partially supports restoring the machine’s original state, which is especially important when handling malware. For such a machine, restoring it requires the user to stop it, remove the old volume, create a new volume with the desired snapshot, and associate it with the machine. In this example, to make things easier, all these actions were bundled into a single action of restoring the machine in the API wrapper.
Once we wrote the API wrapper, creating the new AWS machinery to control existing instances became a much easier task.
However, we still needed to tackle the goal of utilizing the cloud’s elasticity to create an auto-scaling infrastructure. This feature did not exist in any other Cuckoo machinery, thus adding further complexity to this task.
In a scenario where all the pre-configured machines are occupied, our machinery will instantly scale up by creating new machines and adding them to the Cuckoo internal database (DB). The pre-configured machines will then be available for each run of Cuckoo, but the new machines will be terminated after use.
To simplify things, the user can opt to prepare (but does not have to) any number of pre-configured machines with the only mandatory machine to install being the main Cuckoo nest.
One limitation we needed to deal with is that adding or removing VMs from the machines’ DB is not a typical behavior for the Cuckoo machinery. To get around this, similar to what we did with the API wrapper, we created an additional DB component to handle the removal of machines.
Initial Design Diagram
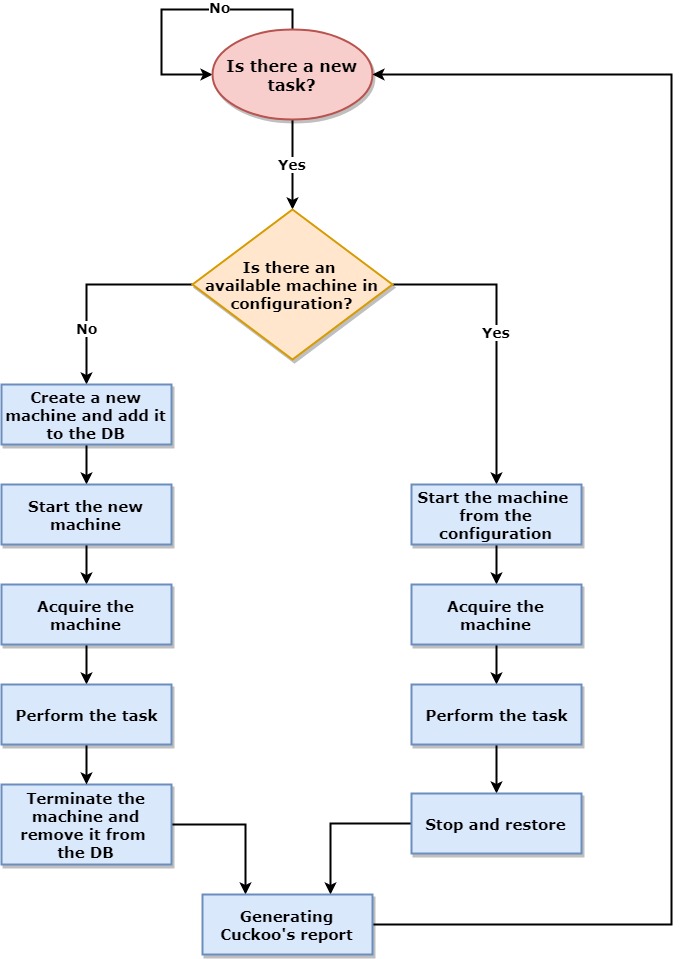
Acquire the machine – The operation of locking one machine with a task (the machine becomes unavailable).
Configuration – The configuration that holds the number of machines that the user pre-defined for the Cuckoo system (they will be available for each run of Cuckoo).
Final Design
We developed this new machinery according to the initial design and started to run tests. It worked correctly but didn’t comply with one very important demand, speed, as the processing time took about 8 minutes. This is far beyond the reasonable time for a single analysis (compared to VirtualBox).
Due to the nature of the EC2 instance, it can’t skip the OS initialization phase. Therefore, the time for the creation of the Cuckoo report was consumed by both the OS boot and the Cuckoo analysis time.
To improve the performance, we needed to make a special alteration: enable the user to configure the number of machines that are ready to perform a task (up and running).
The user defines the size of a pool which contains machines that were already started in advance. Whenever a machine from the pool starts a task, the system will start a new machine and add it to the pool. Thus, there will always be a constant number of ready machines for the user’s requests.
Cuckoo will see this pool as available machines and will pick the oldest one. As a result, the machine that needs to handle a new task will probably be ready immediately to process the task.
Final Design Diagram
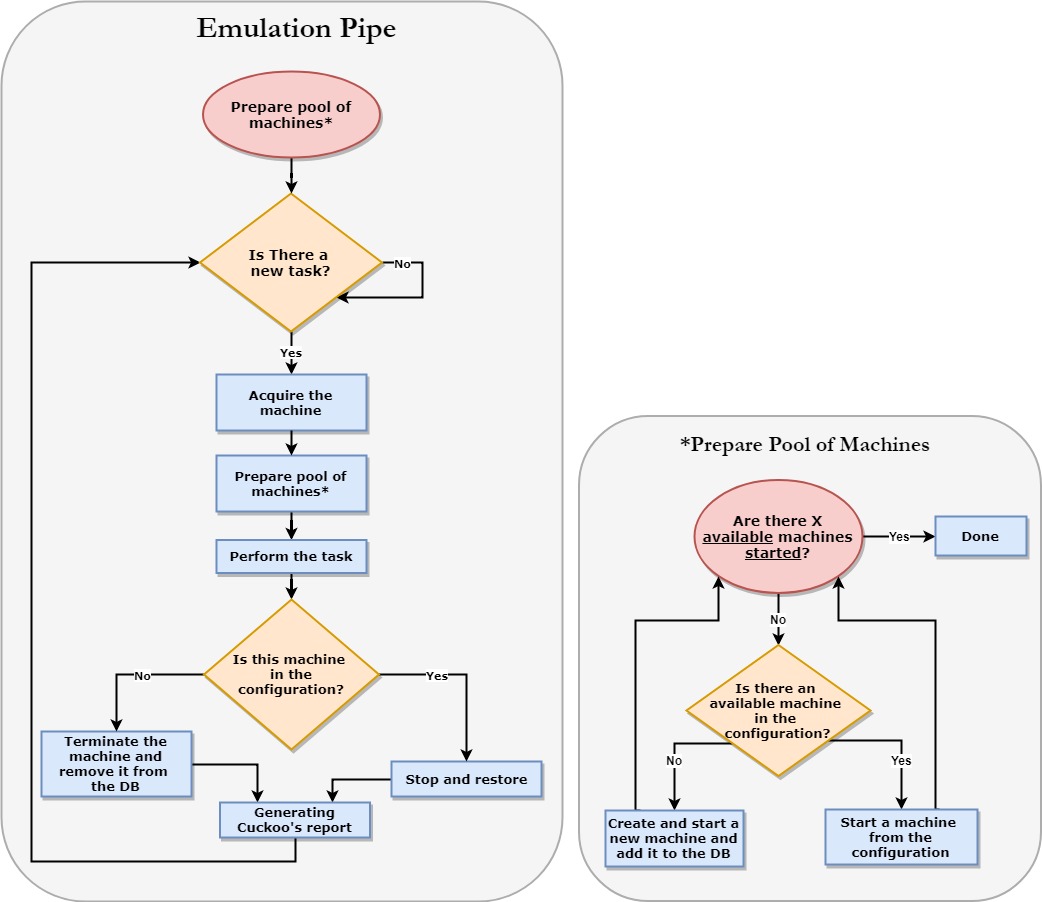
X – The parameter given by the user that represents the number of machines that should be powered on and ready to handle tasks. This does not necessarily have to be equal to the number of tasks.
Before Initialization – The number of machines (X) that are powered on and ready to perform the tasks before the initialization process begins.
Acquire the machine – The operation of locking one machine with a task (the machine becomes unavailable).
Available machines in the configuration – Machines that are not necessarily up and running but are available to be started in our configuration.
Let’s look at the following user scenario. Alice usually has 34 tasks to perform in parallel, so when she initialized her Cuckoo system, she pre-configured 34 machines (in addition to the mandatory Cuckoo nest). Alice’s configuration holds 34 machines + the Cuckoo nest.
One day, Alice has 52 tasks that should be performed at once, so she wants to have 52 machines that are available and already started. She defines the size of the pool of the machines to be 52, and sets X = 52. Before the initialization of the system, the machinery will create an additional 18 machines and start them. After these 18 machines perform Alice’s tasks, they will be terminated. The remaining pre-configured 34 machines will be restored to their original state.
The next day, Alice only has 16 tasks to be performed at once. She sets X = 16. In the “Before Initialization” stage, only 16 machines (out of the 34 pre-configured) are started in advance.
As a result, Alice was able to perform all of her tasks in parallel with great performance, without wasting any expensive resources.
What’s Next?
Amazon just recently released a hibernating option for Linux systems. During the stopping operation, it saves the contents from the instance’s memory. When starting the instance, the volume is restored to its previous state, the RAM contents are reloaded and the processes that were previously running on the instance are resumed. Once it becomes available on Windows systems, utilizing this important feature could be very beneficial to improve boot time.
Currently, the machinery creates new machines on a single subnet. However, a single subnet is limited and might cause errors if it overflows. Supporting multi-subnets would solve such issues.
This task was a big challenge for us, and we plan to keep on updating this project with more features as we believe that this could be beneficial for many people in our community. Malware, beware!
Click here to access Cuckoo SandBox for the Cloud repository






