Labeless Part 5: How to Decrypt Strings in Boleto Banking Malware Without Reconstructing Decryption Algorithm.
October 3, 2018

In this part we show how to decrypt strings present in the module of Boleto malware – without reconstructing the decryption algorithm. If you’re new to all this Labeless stuff though, please refer to the previous articles in this series as they will be helpful in explaining what’s going on here.
From all of the possible goals the one for this article is decrypting strings “on the fly” without digging into algorithm internals. For today’s victim we chose the not so shy, modest and innocent malware described above, named Boleto.
We will use OllyDbg 2.01 for executing script on debugger side. Real case example where x64dbg is used will be provided in the next article in this series.
Contents
Decrypting Strings Without Reconstructing The Algorithm
Boleto is a banking Trojan which uses a legitimate signed executable to bypass anti-virus scans and launch its malicious payload. The malware’s arsenal, though, is not limited only to this trick.
Boleto consists of two main injected modules, one of which is protected with a highly sophisticated Themida solution. In addition, internal strings in all modules are encrypted which is why it is not clear what’s going on inside the modules upon our initial glance.
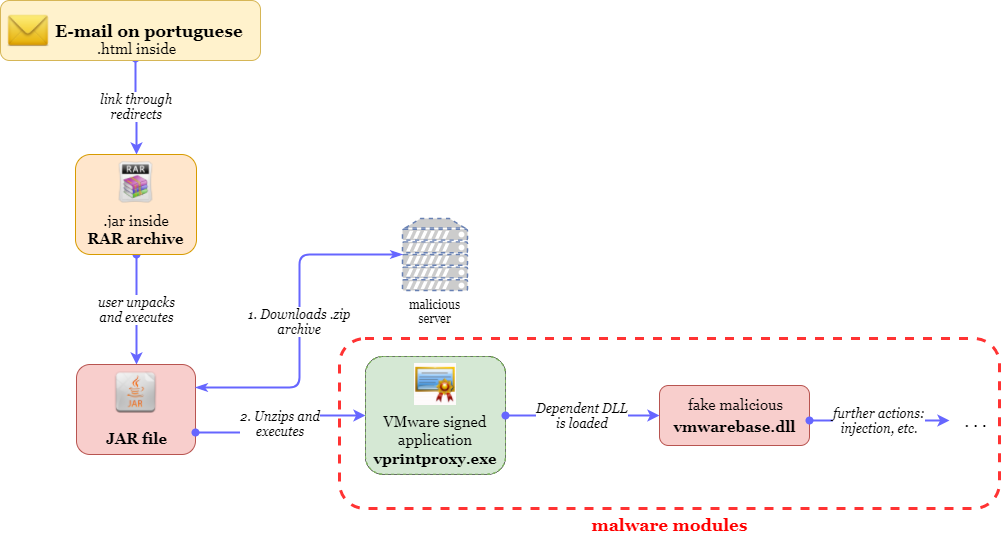
The following scheme is used to launch the malicious payload:
Meticulous research was conducted into Boleto by the Check Point Research team – as seen here:
https://blog.checkpoint.com/2017/10/18/boleto-perfect-inside-job-banking-malware/
The details of this research is demonstrated here:
https://research.checkpoint.com/perfect-inside-job-banking-malware/
What is left behind the scenes is how exactly these results were obtained. We unveil one part of the analysis and show how we have decrypted strings present in a fake dependent DLL without reconstructing the decryption algorithm.
Decrypting strings without reconstructing the algorithm
Let’s see how exactly Labeless allows us to interact with debugger. To begin with, let’s take a quick look at our patient. As mentioned in the previous article(link to it), OllyDbg 2.01 is used throughout this article.
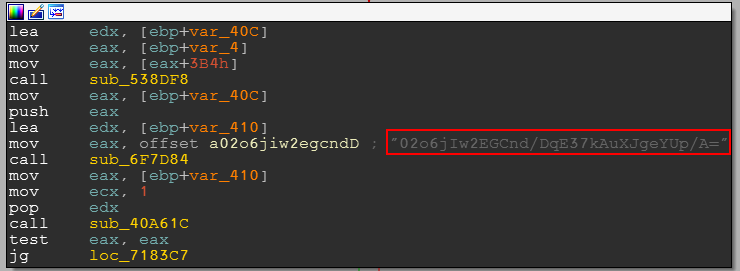
The below is what we get after opening fake dependent DLL – the focus being on strings:
And a lot of cross-references to what appears to be the decrypt function:
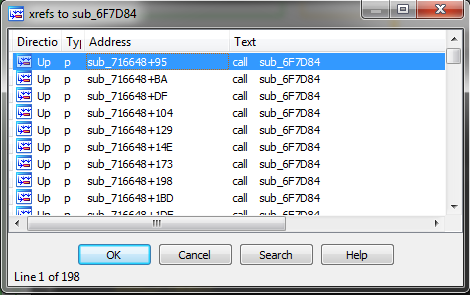
Not that informative, right?
If you’re on the impatient side, or simply like teasers, and want to get it all at once, you may skip right to the `Results` section and see what we get after all the steps are performed. You could then return here for a step by step understanding of how we achieved it.
Even before writing the scripts to decode those strings, we would like to make our database more readable. As the sample is written in Delphi, we will use IDR tool which is specially crafted for resolving lots of Delphi-specific stuff:
https://github.com/crypto2011/IDR.
(To be honest, the topic of reconstructing Delphi samples is interesting by itself and may be a subject of one of our future articles.)
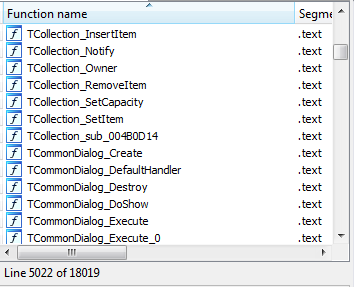
After applying some IDR magic, we get a lot of resolved function names:
 As well as internal objects, as shown in the screenshot before the call to the function where the string is being deciphered:
As well as internal objects, as shown in the screenshot before the call to the function where the string is being deciphered:
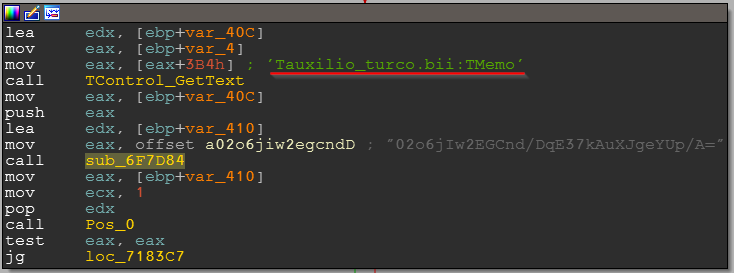
We see that text is read from the `Tauxilio_turco.bii:TMemo` component which undoubtedly adds some details to the research.
Let’s rename the function “sub_6F7D84”, to make it stand out from the crowd, and from now on it will be called “decrypt_string”.
Now we want to decipher the strings as the next step in the researching of this malware.
Before considering the option to reconstruct the algorithm, let’s examine the call graph inside this decoding routine:

Looks pretty impressive, doesn’t it? Now it seems like we have an idea that we do not want to reconstruct everything in its entirety.
So what exactly do we want to accomplish with the help of Labeless? We will call the decryption routine from malware code and define its arguments by ourselves. So effectively we take working code, change argument(s) for the function and execute it – like this:
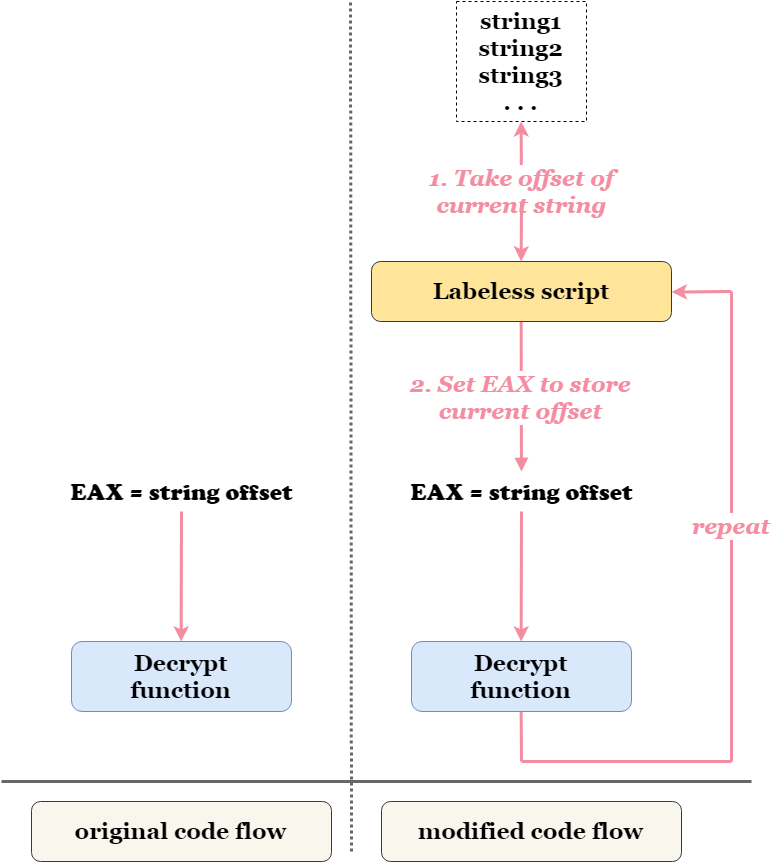
To make this scheme work we have to find some place in the code where the target function is called. We then see how exactly it is called and change its arguments. The changing of the arguments will occur for each encrypted string present in malware.
So the function is taken as a black box and we do not bother with implementation details at all.
As we recall from the previous theoretical article, there are three steps required to be accomplished when using Labeless scripting:
We will discuss all three points in turn.
To accomplish the first part, the following steps are taken:
The main part of the script is as follows:
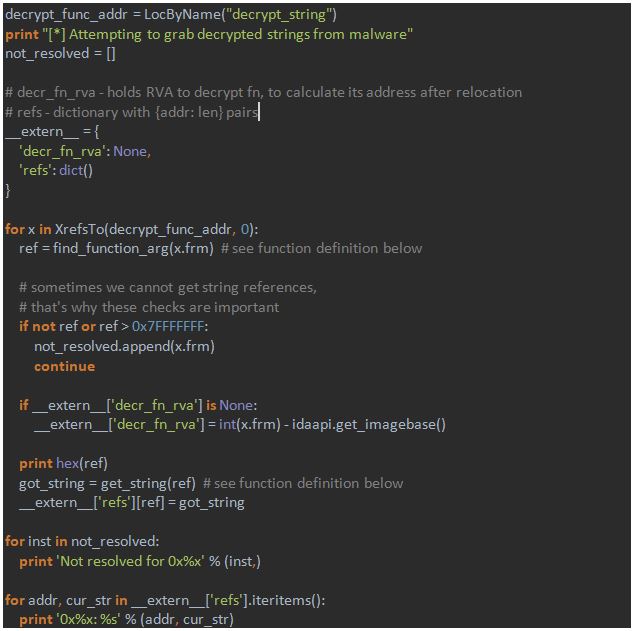
Note that encrypted strings are written to the `__extern__` variable to be passed to the debugger.
There are two functions we have to implement – they are outlined in bold in the listing above:
To define `find_function_arg` we have to look how string offsets are passed to `decrypt_string` function. As seen in the screenshot below, the offset is pushed to EAX:![]()
We may want to check other places if it’s the same there – and indeed it appears to be the same:
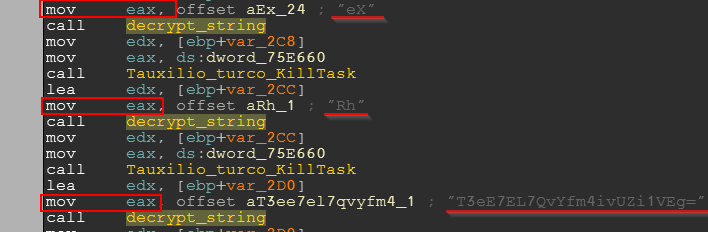
Just in case, we give additional chances for the function to succeed and ask it to search for “mov eax, offset” instruction within the five previous instructions before the call, not just one previous instruction. The whole function is thus defined in the following way:
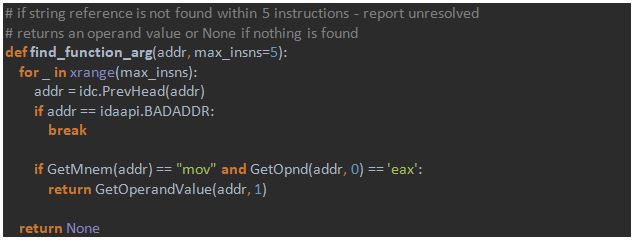
As we can see, it’s pretty simple: function returns offset if it is found – and “None” otherwise.
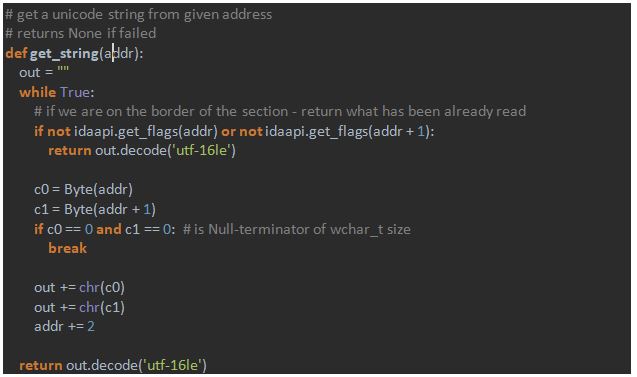
To define `get_string` function we take a look at the way strings are present in the malware module:
![]()
`UTF-16LE` means that string is in Unicode, thus each symbol occupies 2 bytes (wchar_t type).

All things considered, the `get_string` function is simple as well:
The whole script resides here:
https://gist.github.com/a1ext/1524608512e57c9a82ba7cd166d62e48
Note that script should be executed via Labeless window – just press the button “Remote Python execution” as explained in the “Theory” section above:

Script should be placed in the left-sided window. Now we press “Run” and check the output:

Encrypted strings are here along with corresponding addresses in the code where they are used – nice! Now we can proceed to OllyDbg side.
First thing to accomplish in Olly is to step right before any `decrypt_function` call – it doesn’t matter which one exactly:

We see that EAX points to contents of encrypted string and EDX points to another pointer with contents of decrypted string – it will be set by decryption routine. These strings are Delphi Unicode strings which are described with the following structure:
struct DelphiString {
int length;
wchar_t contents[length];
};
Registers contain pointers not to the beginning of the structure but to its “contents” field:

Each cell represents one byte. The first four store string length whereas others are for the contents itself. Terminating null is not mandatory for Delphi strings.
Note that all researched labels are synchronized with IDA database within debugger – even despite image base difference. Synchronization of names and labels is described in the third part of this series.
Now we can take a VM snapshot, press the “step over” button and see how exactly the string is stored when it’s decrypted:
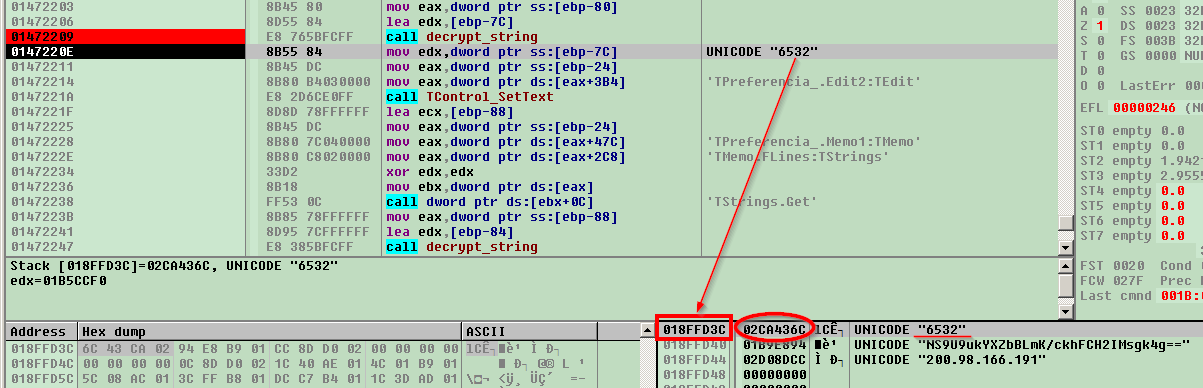
EDX points to another address which in turn holds physical string. With this information in hand we can revert VM back to the snapshot that was just created to the point just before executing `decrypt_string` call.
We have the list of encrypted strings and the storage method of the decrypted string. The idea for Labeless script is the following:
Now let’s put everything together in the script:
https://gist.github.com/a1ext/f27748f172a36428994b06538efe27a1
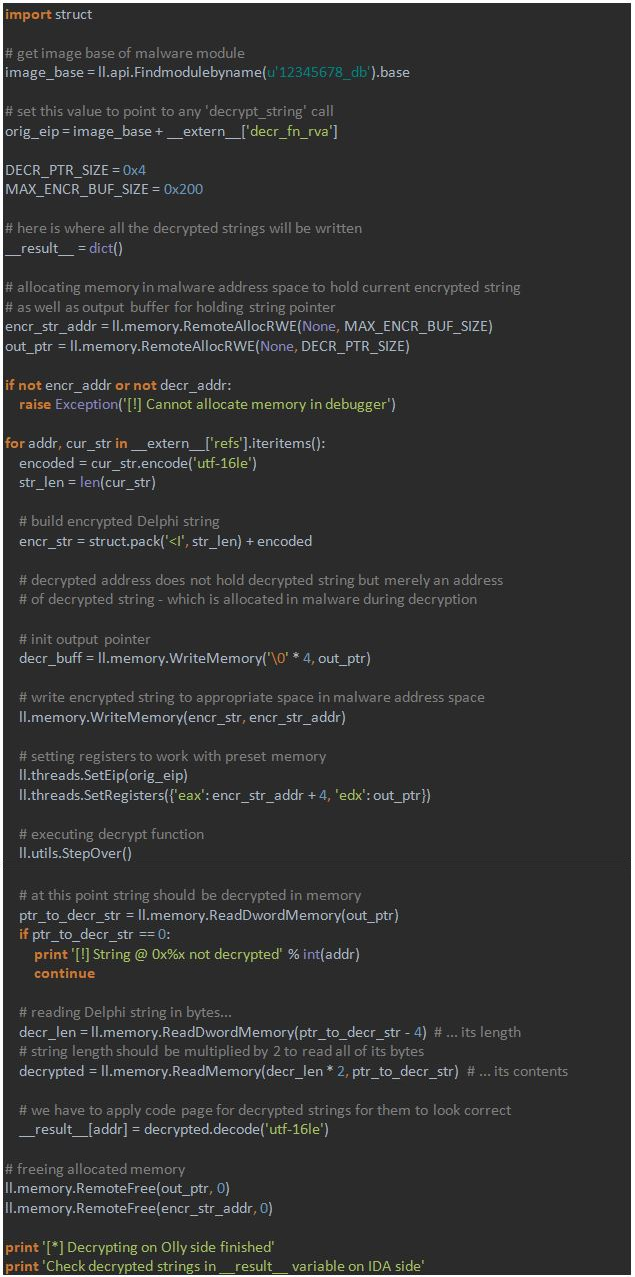
Pay special attention that encrypted strings are being read from `__extern__` variable and decrypted strings are being written to `__result__` variable.
There are functions from Labeless API here and there in the script. They stand out from the rest because of their structure `ll.[module].[func]`. Please refer to the previous article for more info on the API.
Also note that Unicode string contains 4 bytes of length at its beginning. We took this into account in the code.
Why do we use string encoding to UTF-16LE? Internally,`__result__` variable uses JSON serialization to transfer the Python variable to IDA side. Serialization may fail if usual Python str is passed and special symbols (non-serializable by default codec) are encountered there. To avoid this peculiarity we pass unicode string so that it can be serialized in any case.
“LE” in “UTF-16LE” stands for Little Endian. You can read more about encodings here:
http://kunststube.net/encoding/
and about “UTF-16LE” in particular here:
http://www.herongyang.com/Unicode/UTF-16-UTF-16LE-Encoding.html
Let us execute both scripts, one for IDA and one for Olly (left side for IDA script and right side for Olly):
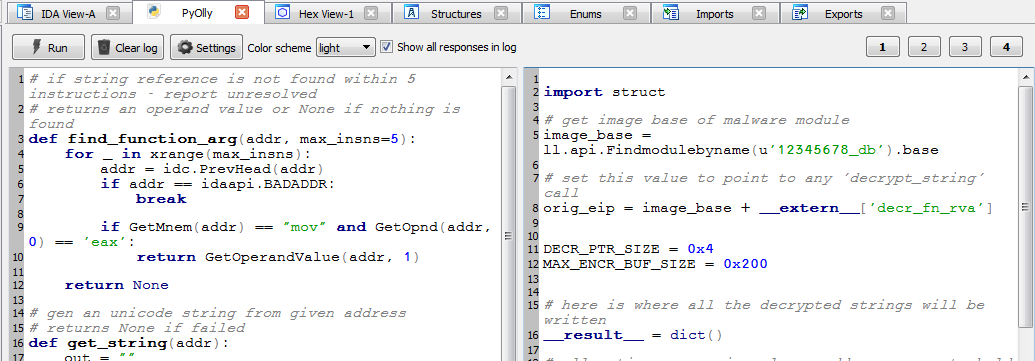
You may ask: why to execute IDA script for the second time? To be honest, this script can be deleted from the window. We left it in here to underline the connection between results of IDA script which are passed to debugger side and used in Olly script aftermath.
When two scripts are present in Labeless windows, they are executed one by one, from left to right. First goes IDA script, then script for Olly. Press `Run` button at the top left corner and see it for yourself.
After some waiting time, the below output indicates that the task is completed:

Now we have all the decrypted strings it’s time to propagate them to IDA database. So far we haven’t seen them…intrigue is growing… What will we see there? Keep on reading and the mystery will be solved.
The easiest and the most pleasant step: propagating prepared information to the database. We clean the right side of the Labeless script window indicating that we’ve finished with code execution on the debugger side. After that we insert IDA script to apply decrypted strings as comments next to the function calls:
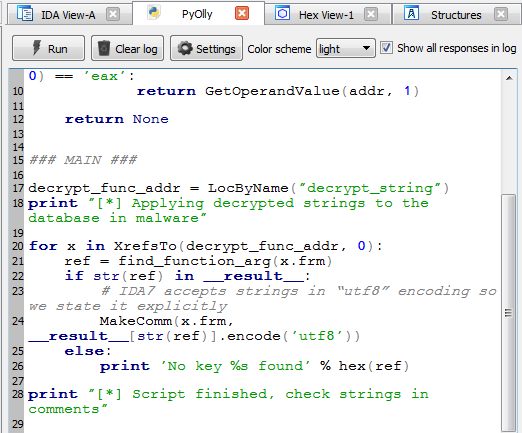
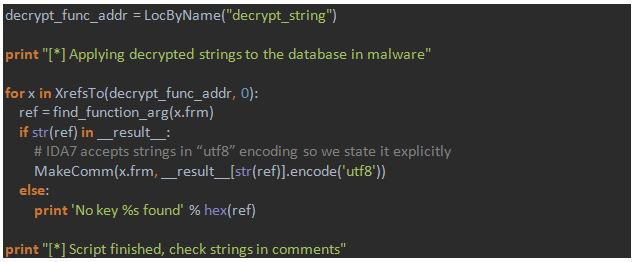
Here is the main part of the script (function `find_function_arg` is the same as in the first part script). The whole script can be downloaded via the link below:
https://gist.github.com/a1ext/8396d9e151c7fcee100babe9602215f6
And here is the script execution log:
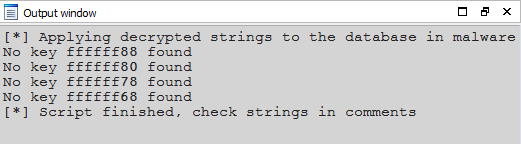
Now we are ready to check the actual resolved results!
After all the steps have been performed, we can enjoy the strings right in the code:
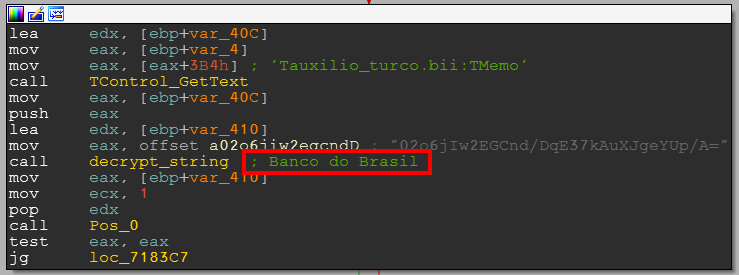
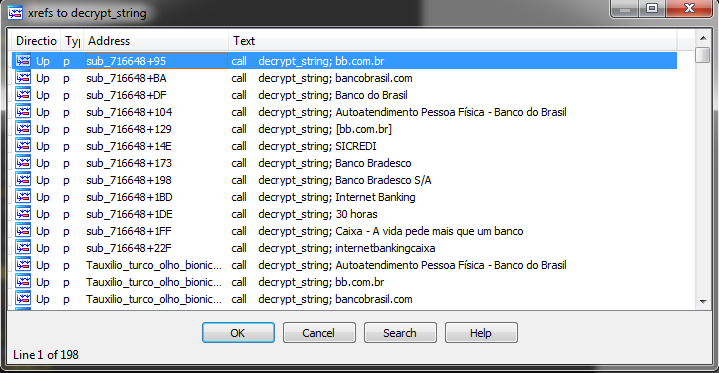
As well as navigate those strings via cross-references to decrypt function:
Note how neatly IDA displays Unicode strings with special symbols (ú in this case) in comments:
![]()
Some of the strings were not decrypted because malware determines strings’ offsets in runtime. There are only four such discrepancies out of almost 200 strings so we will accept it and look for unresolved strings in debugger.
To conclude, we have used malware against itself; malware has the functionality to decrypt strings so we used it right from the original code. We didn’t bother with algorithm reconstruction, ripping assembly instructions, re-writing code in a high-level language – nothing even remotely close to it in fact.
Instead we performed a high-level research based on scripting which doesn’t rely on implementation details of malware routines and these script templates can be re-used in future researches.
Stay tuned – in the next part of this series we will evolve with Labeless scripting even further. We will show how to decrypt function names by their hashes – without reconstructing the algorithm behind it – in a sophisticated and evil malware, Ngioweb, which is a part of the infamous Ramnit Trojan bot network.
MD5: 910050bc1fcea33836fa2e9978bbea10
SHA1: 8e48a22aba894d0fc81501b88c5fc9c53a7671c0
Hashes of the malicious ZIP archive are provided above, the module researched in the article is the one with `prs.png` name inside the archive.
Labeless github repository:
https://github.com/a1ext/labeless
Latest Labeless release version:
https://github.com/a1ext/labeless/releases/latest
IDR – Delphi research tool:
https://github.com/crypto2011/IDR
Scripts:
Credits go to Alexander Trafimchuk (a1ex.t), author of Labeless and an all-round jolly good fellow.
Other credits go to (sorry guys, we know only your nicknames):





